集合(Set)
- 不能添加重复元素
- 应用:
- 客户统计,词汇量统计
实现
1 | public interface Set<E> { |
基于二分搜索树.
- 创建一个 Set 接口,定义 Set 的基础方法
- 创建 BSTSet 类,实现 Set 接口,内部实现二分搜索树的结构
- 注意:使用泛型后,需继承 Comparable (二分搜索树里的数据必须是可比较的)
1 | package dataStructure.set; |
- 写完这个后,发现和二分搜索树不是完全一样吗,对!二分搜索树就已经实现了 Set 的所有功能
基于链表
- 实现Set接口,内部实现LinkedList的结构(前文中自制的)前文地址
- 除了添加方法需要进行设置一下,其他的都调用链表方法就行
1 | public class LinkedListSet<E> implements Set<E> { |
时间复杂度分析
- 最理想的情况下,是满二叉树,h层的话,一共有2^(h-1)个节点
- h = log2 (n+1)
- O(log2 n) = O(log n)
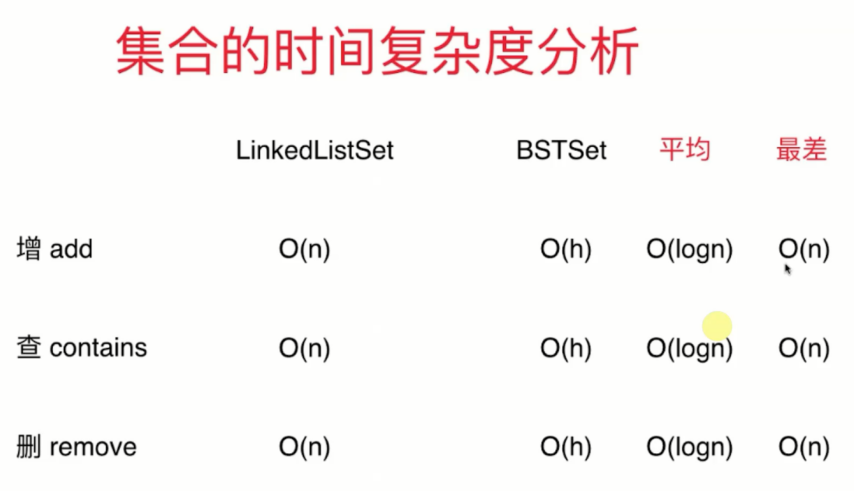
- 这两种时间复杂度的差距其实是非常大的,可以用一张图来更好的看出来

有序无序
- 一般来说,集合中元素可以轻易的进行排序,就是有序集合
- 有序集合基于搜索树实现的
- 无序集合有 基于链表实现的、基于哈希表实现的
映射(Map)
- 存储(键,值)数据对应的数据结构(Key,Value)就是映射
- 根据Key ,寻找Value
- 非常容易通过链表或二分搜索树实现
实现
1 | public interface Map<K, V> { |
基于链表
- 需要创建一个 getNode 的方法来辅助实现 增删改查 方法
1 | public class LinkedListMap<K, V> implements Map<K, V> { |
基于二分搜索树
定义二分搜索树类
1 | public class BSTMap<K extends Comparable<K>, V> implements Map<K, V> { |
辅助方法
1 | // 返回以node为根节点的二分搜索树中,key所在的节点 |
常见方法
1 | public int getSize(){ |
增加元素
1 | // 向二分搜索树中添加新的元素(key, value) |
删除元素
- 删除元素和二分搜索树中的删除元素很相似
1 | // 返回以node为根的二分搜索树的最小值所在的节点 |
复杂度
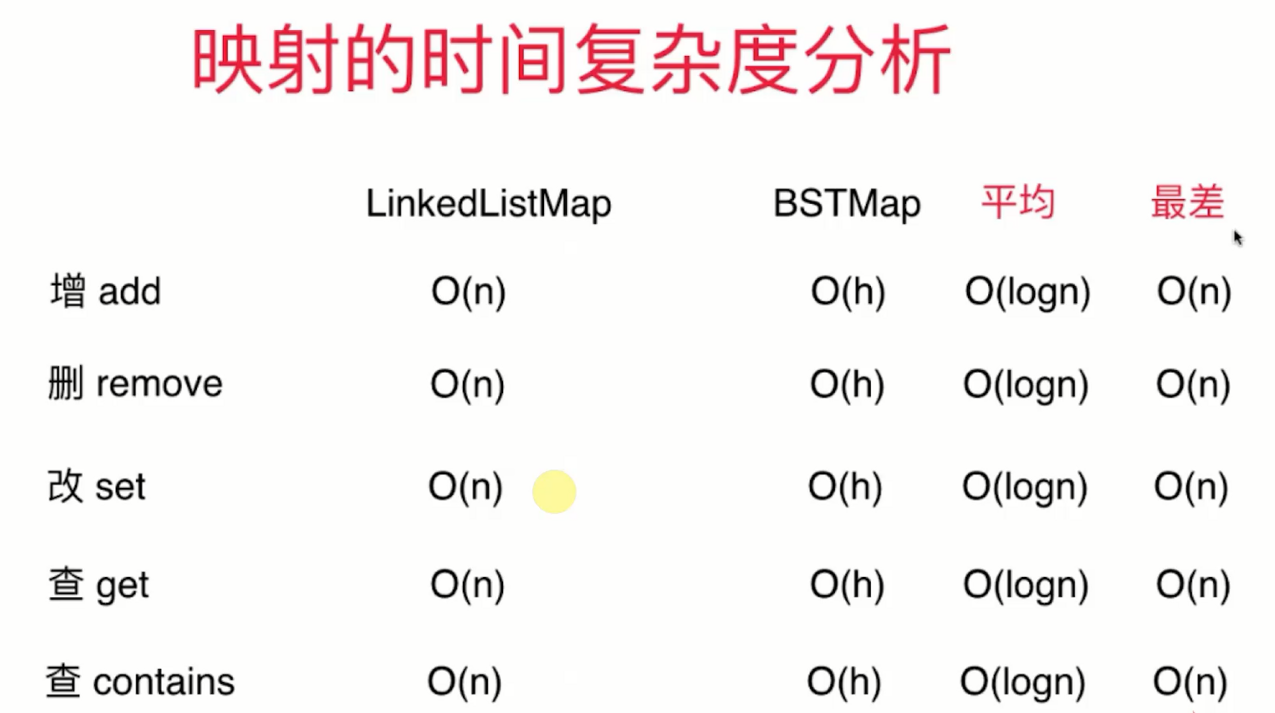
有序无序
- 根据键是否有顺序性,判断映射为有序无序
- 基于搜索树实现的是有序的映射
- 基于哈希表实现的是无序的映射
集合和映射关系
- 可以互相转换
- 如:有了映射的底层实现,可以将value看为0,这样就实现了集合