快排的算法在平均状况下,排序效率为 O(N*LogN),运算效率是最高的,所以最受欢迎。而且在快速排序的算法中还体现着 分冶 思想,这几天我学习了一下这个算法,整理一下他的算法思路。
算法原理
快速排序算法使用分冶法来把一个序列分为两个序列
- 从数列中挑出一个元素,称为“基准”(pivot)
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面
- 在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作
- 递归地把 小于基准值元素的子数列 和 大于基准值元素的子数列 排序
下面的图片来自于维基百科,通过看这张图可以观察到使用该算法后数据的变化
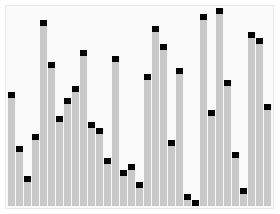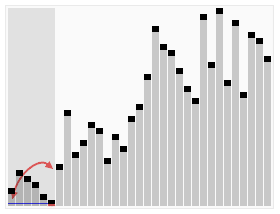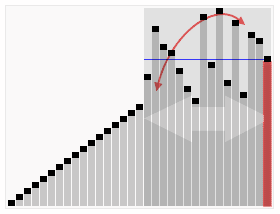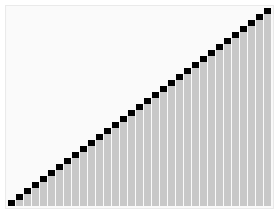
白话快排
我在CSDN看到一篇非常好的文章讲解了这个算法的原理,在这里转载过来一部分
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)
以一个数组作为示例,取区间第一个数为基准数。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
72 |
6 | 57 | 88 | 60 | 42 | 83 | 73 | 48 | 85 |
初始时,start = 0; end = 9; pivot = a[i] = 72
由于已经将a[0]中的数保存到pivot中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比pivot小或等于pivot的数。当 end=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; start++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从start开始向后找一个大于X的数,当start =3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; end–;
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
48 |
6 | 57 | 88 |
60 | 42 | 83 | 73 | 88 |
85 |
start = 3; end = 7; pivot =72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当end =5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; start ++;
从i开始向后找,当start =5时,由于start == end退出。
此时,start = end = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
48 |
6 | 57 | 42 |
60 | 72 |
83 | 73 | 88 |
85 |
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了
对挖坑填数进行总结
1.start end pivot共三个参数; 将基准数挖出形成第一个坑a[start]。
2.end–由后向前找比它小的数,找到后挖出此数填前一个坑a[start]中。
3.start++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[end]中。
4.再重复执行2,3二步,直到 start == end,将基准数填入a[start]中。
照着这个总结很容易实现挖坑填数的代码:
代码示例
- 在这个类中,为了方便理解,我创建了多个方法互相调用,并在函数上面加上了注释
1 | public class QuickSort { |
优化
- 在上面可以发现,代码的基准一直选取的是第一个数,在某些糟糕的情况下,该算法效率并不佳
- 过段时间,我会再补上优化的部分